

The PDF Image to Text tool is designed to convert scanned PDF documents into searchable and editable text. It utilizes OCR (Optical Character Recognition) feature to recognize the text within the scanned PDF and turn it into digital text that can be edited and searched.
Yes, the PDF OCR tool works only on scanned PDFs because it is designed to recognize and extract text from images. If you have a PDF document that already contains digital text, OCR is unnecessary.
Yes, the PDF OCR tool supports multiple languages. You have to select the language of the text you prefer to extract from the scanned PDF document. The tool will then use OCR to recognize the text in that language and convert it into digital text.
The OCR process time depends on the PDF document's size and the text's complexity. However, the PDF OCR tool is designed to process PDF documents quickly and efficiently. Typically, the OCR process can take a few seconds to a few minutes for a typical PDF document.
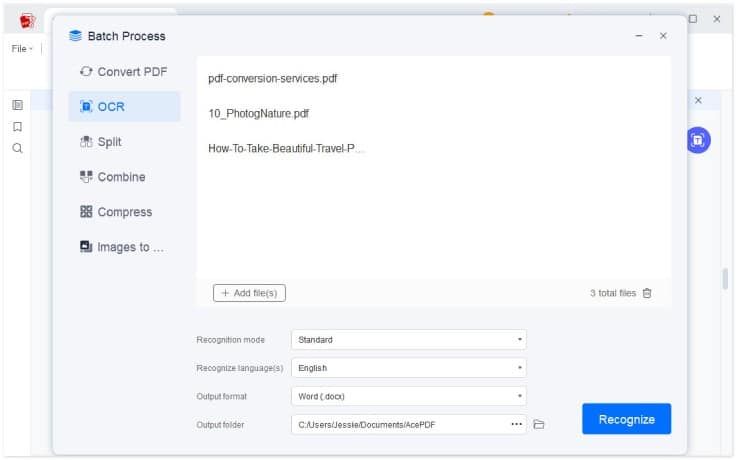
The PDF OCR tool allows you to convert PDF to Text from a large number of PDF files. You can also batch-process various PDF documents and extract text from all of them at once.
Yes, the PDF file size that can be processed by the PDF OCR Tool is limited. However, this limit varies depending on the specific tool you are using. Some tools may have a limit of 100MB, while others may be able to process larger files.











